BeingBeyond is a start-up company on foundation models for embodied AI.
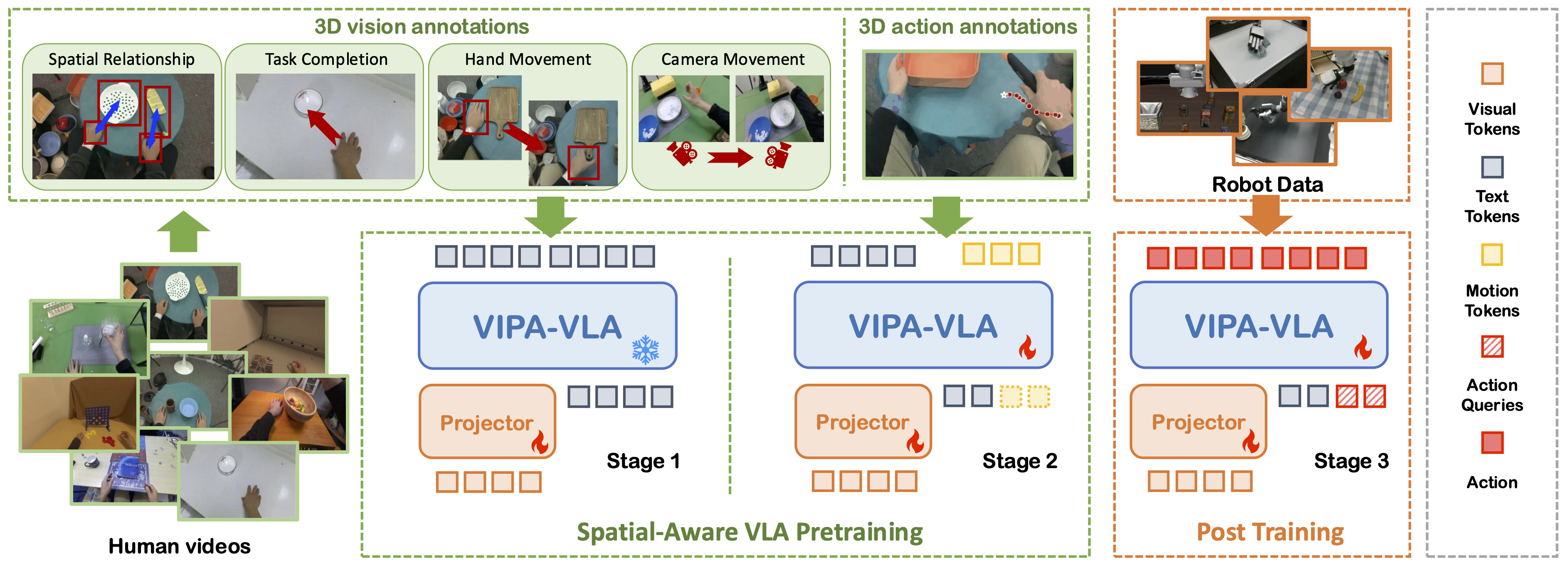
Spatial-Aware VLA Pretraining through Visual-Physical Alignment from Human Videos
Dec 15, 2025VIPA-VLA learns 2D-to-3D visual-physical grounding from human videos with Spatial-Aware VLA Pretraining, enabling robot policies with stronger spatial understanding and generalization.
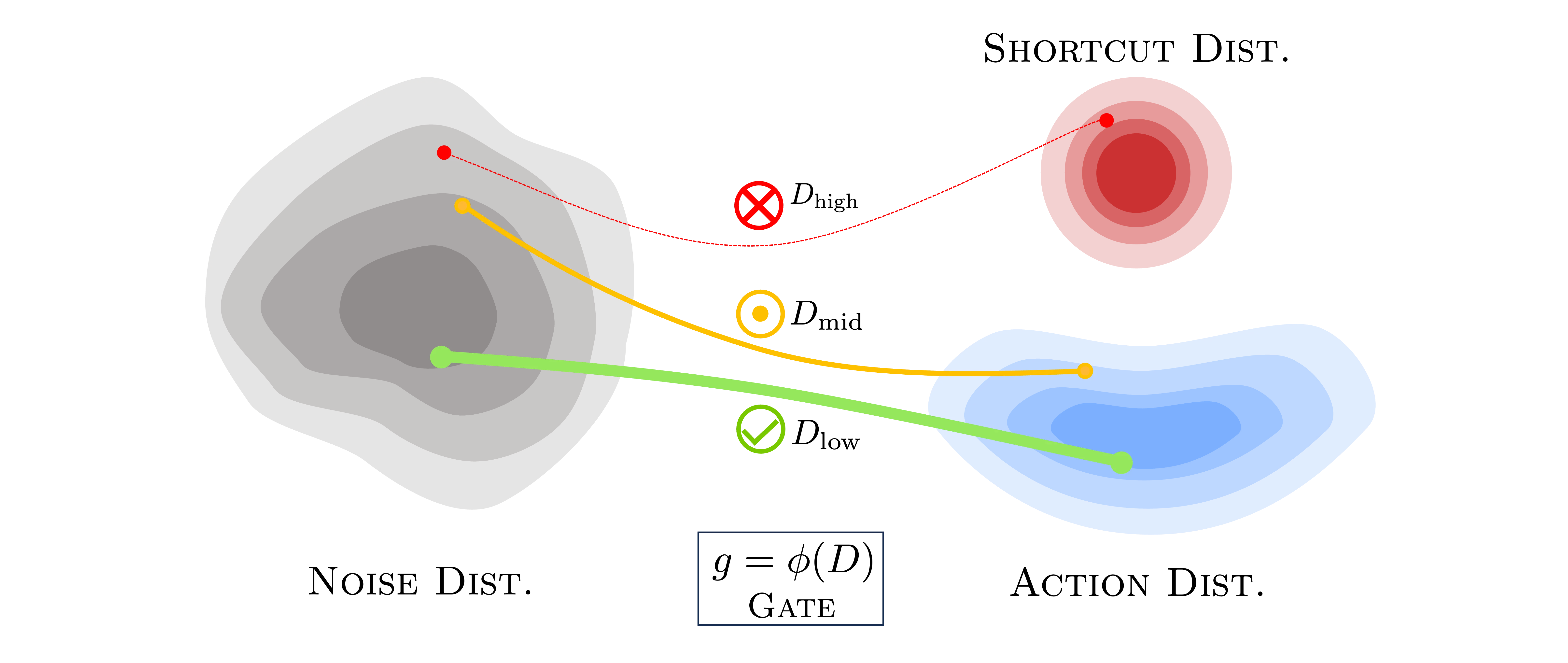
DiG-Flow: Discrepancy-Guided Flow Matching for Robust VLA Models
Dec 01, 2025DiG-Flow is a plug-and-play module for flow-matching based VLAs that rebalances control between the autoregressive foundation model and the flow expert. It embeds model inputs and flow outputs into a unified discrepancy space and uses this signal to gate the flow path, preventing shortcut transports that bypass the pretrained model and steering the expert toward more general, robust actions.
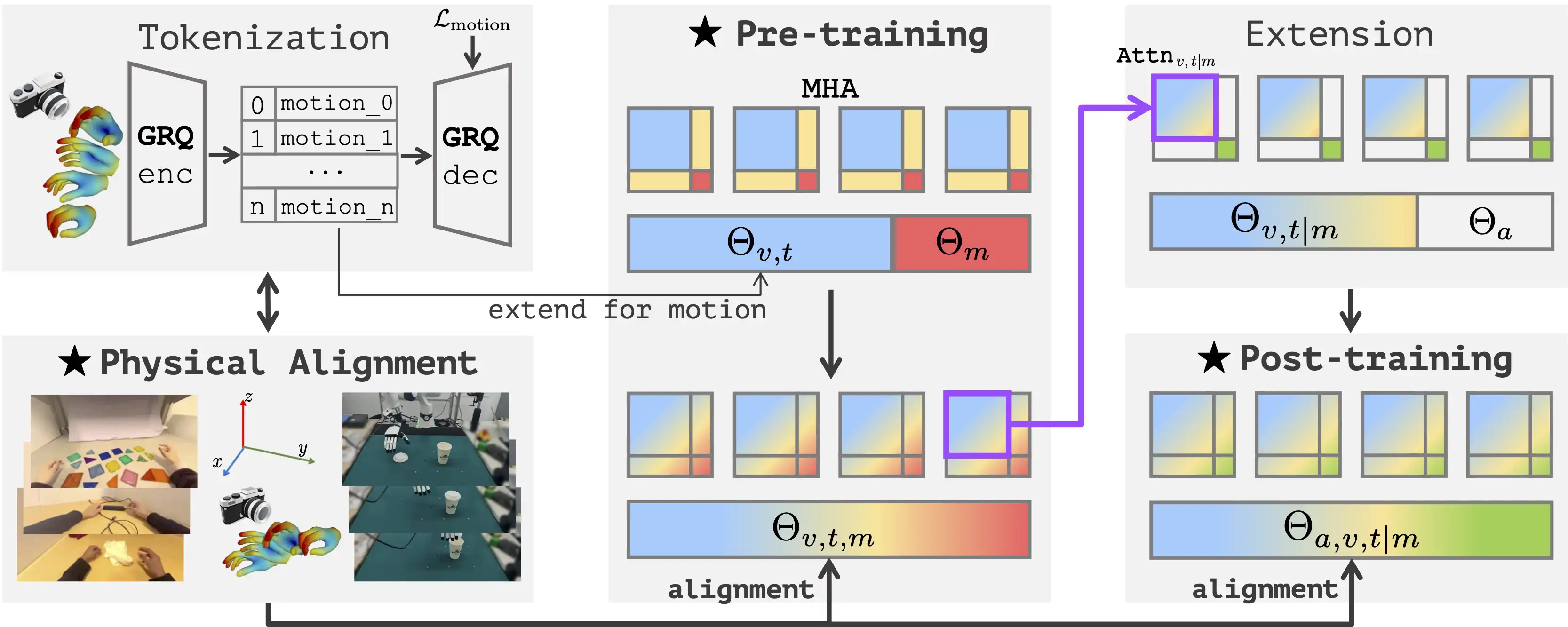
Being-H0: Vision-Language-Action Pretraining from Large-Scale Human Videos
Jul 21, 2025Being-H0 is the first dexterous Vision-Language-Action model pretrained from large-scale human videos via explicit hand motion modeling. By explicitly modeling hand motions, Being-H0 seamlessly transfers from human hand demonstrations to robotic manipulation.